Содержание
Разве́дка на осно́ве откры́тых исто́чников (англ. Open source intelligence, OSINT ) — разведывательная дисциплина, включающая в себя поиск, выбор и сбор разведывательной информации из общедоступных источников, а также её анализ. В разведывательном сообществе термин «открытый источник разведывательных данных» (англ. open information source ), который указывает на общедоступность источника (в отличие от секретных источников и источников с ограниченным использованием), но он не связан с понятиями «просто источник информации» (англ. open source information; OSIF ), означающий любую находящуюся в пространстве СМИ информацию. [1] Это понятие не тождественно «публичной разведке» (англ. public intelligence ). Также его не стоит путать с понятием «открытое программное обеспечение» (англ. open-source software ). [1]
По утверждениям аналитика ЦРУ Шермана Кента 1947 года, политики получают из открытых источников до 80 процентов информации, необходимой им для принятия решений в мирное время. Позднее генерал-лейтенант Самуэль Уилсон (англ.) русск. , который был руководителем РУМО США в 1976—1977 годах, отмечал, что «90 процентов разведданных приходит из открытых источников и только 10 — за счёт работы агентуры» [2] [3] .
Содержание
История [ править | править код ]
История OSINT начинается с формирования в декабре 1941 года Службы мониторинга зарубежных трансляций (англ. Foreign Broadcast Monitoring Service, FBMS ) в Соединённых Штатах Америки для изучения иностранных трансляций. Сотрудники службы записывали коротковолновые передачи на пластиковые диски, после чего отдельные материалы переписывались и переводились, а затем отправлялись в военные ведомства и подавались в формате еженедельных докладов [4] . Классическим примером работы FBMS является получение информации об успешности проведения бомбардировок на вражеские мосты путём получения и анализа изменения цен на апельсины в Париже [5] .
"Кто владеет информацией — тот владеет миром"
метки
Самые популярные статьи






Написать мне


Сбор информации из открытых источников
Сетевой шпионаж или сбор информации?
Интернет может рассматриваться как незаменимый источник информации. Полученные из Сети данные применяются в сфере образования, бизнеса, развлечений, отдыха, медицины и т. д. Но Интернет — это не только информационный Клондайк. Киберпространство уже давно стало ареной сетевого шпионажа, на которой активны различные разведывательные структуры и специальные службы, работающие на правительства, бизнес, криминал. Почему так происходит?
Почему Всемирная Паутина является пространством для добывания чужих секретов? Ответ простой: потому, что в Интернет есть ВСЁ. ВСЁ – это любая информация об общественных или государственных учреждениях, организациях, бизнес-структурах, частных лицах.
Эта статья не ставит своей целью пропаганду неэтичных и, тем более, незаконных способов добывания информации, — оставим это профессионалам. Речь идет о сборе данных законными методами, используя открытые источники информации . Открытыми источниками называются источники информации, доступ к которым происходит легально, на законных основаниях.
Нужно заметить, что к открытым источникам следует отнести не только те, к которым возможен публичный доступ, но также и те, доступ к которым технически возможен по причине, например, непрофессионализма или халатности службы защиты информации или системного администратора.

Фото Search Engine People Blog
Поиск необходимой информации с использованием открытых источников взят на вооружение многими гражданскими и военными структурами, работающими на поприще разведки и промышленного шпионажа. Положительные стороны сбора информации с помощью открытых источников очевидны: отсутствует риск провала агента и, следовательно, ущерба для собственной репутации.
Такой подход, к тому же, позволяет значительно экономить средства, ведь не нужно тратиться на кражу информации, если её можно взять вполне легально! Открытые источники информации могут быть различными, но именно Интернет является наиболее удобным и "технологичным" средством доступа к разного рода данным.
Информационные отделы крупных (и не только) компаний а также бизнес-разведчики разного калибра неустанно исследуют Киберпространство в поисках информации (отчетов, компромата, личных данных сотрудников и т. д.) о бизнес-партнерах различных компаний или их конкурентах. Очень часто информация, собранная из открытых источников, используется для проверки деловой репутации компании-контрагента и принятия правильных решений о сотрудничестве.
Например, перед заключением крупной сделки с некой компанией, заказчику бывает необходимо выяснить, сможет ли контрагент реально выполнить свои обязательства. Для этой цели исследуется находящаяся в открытом доступе информация: архивы СМИ, корпоративные сайты, на которых можно почерпнуть немало информации о хозяйственной деятельности компании.
Открытые источники позволяют выяснить, что компания рассказывает о себе в пресс-релизах, и что говорят о ней другие участники рынка. Важные данные о компании можно почерпнуть из БД (баз данных) государственных органов статистики и регистрации, из архивов арбитражных и хозяйственных судов, в случаях, если компания принимала участие в подобных судебных разбирательствах.
При решении подобных задач 80% занимает работа с открытыми источниками, оставшиеся 20% — обработка и анализ собранных данных. Изучение методик бизнес-разведки проводятся на специальных семинарах и тренингах, которые, при желании, можно найти в Сети.
Где искать?
Доступ к нужной информации в Интернет может быть реализован различными способами. Это могут быть переходы по гиперссылкам , поиск по различным каталогам (сайтов, блогов и т. д.), можно просто вбить запрос в любимый поисковик и просматривать поисковую выдачу. Для определенных целей нельзя обойтись без поиска по специализированным базам данных ( БД ).
Выбор способа "передвижения" по Сети определяется вашей целью и желанием. Если вы выбрали неправильный метод поиска, вам придется переворотить массу информации, чтобы найти тот единственный нужный документ. И положительный результат еще не гарантирован. Коротко рассмотрим каждый из способов:
Переходы по гиперссылкам в поисках необходимого документа среди миллиардов страниц — дело совершенно бесперспективное. Но ссылки, вообще, могут оказаться очень полезны при сборе скрытой информации об объекте (т. н. обратный поиск). Вспомним статью "Как правильно искать в Google 2" и применим оператор [ link: ], благодаря которому можно отыскать все страницы, ссылающиеся на объект нашего исследования.
Например, такие поисковые сервисы, как google.com, alltheweb.com, altavista.com, search.msn.com по запросу [ link:vsepoisk.ru ] выдадут ресурсы, в которых упоминается любая страница сайта vsepoisk.ru. Для поискового сервера Yandex ( yandex.ru ) аналогичный запрос будет несколько отличаться и иметь вид [ #link="vsepoisk.ru" ].
Поиск по каталогам , когда нужно найти конкретный документ, неэффективен, но используется, если нужно найти определенную тематическую информацию. Как правило, в каталогах все ссылки являются профильными, так как их составлением занимаются не программы, а люди. Например, если ведется поиск общей информации по некоторой обширной теме, то целесообразно обратиться к каталогу. Существует огромное количество разнообразных каталогов, в том числе специализированных (узкотематических).
Например, крупнейший каталог ресурсов Интернет — проект "Открытый каталог" ( dmoz.org ) включает в себя сведения о более 4 млн. сайтов. Один из наиболее популярных русскоязычных каталогов находится по адресу list.mail.ru . Кроме каталогов общего профиля, в Сети много специализированных каталогов. Так, по адресу www.kinder.ru находится объемный каталог, посвященный ресурсам для детей. Введите в строку поиска запрос вида [ каталоги сайтов спорт|живопись|программирование ], и вы получите исчерпывающий набор каталогов на эти, или любые другие темы.
Поисковые машины служат для нахождения в Сети конкретных документов. Проблема состоит в том, что поисковик не является высокоинтеллектуальной системой, которой можно легко объяснить, что вы ищете. Если бы это было так, то он выдавал бы два-три документа — именно те, которые необходимы. Но, обычно, в ответ на поисковый запрос пользователь получает длинный перечень ссылок на страницы, многие из которых не удовлетворяют пользователя.
Такие документы называются нерелевантными (от англ. relevant — подходящий, относящийся к делу). Таким образом, релевантный документ — это документ, который содержит искомую информацию. Понятно, что от умения грамотно формулировать поисковый запрос зависит количество (процент) найденных релевантных документов.
Поиск по базам данных является эффективным методом тематического поиска. Сбор необходимой информации в русскоязычных и зарубежных информационных, образовательных и научных ресурсах очень часто требует больших усилий и может стоить значительных затрат средств и времени.
Применение некоторых методов сбора информации, описываемых в этом разделе, позволяет не только оптимизировать процесс, но и получить достоверную информацию по необходимой тематике, в нужном объеме и при минимальных затратах.
Наиболее оптимальным вариантом представляется работа со специализированными базами данных , которые предназначены для классификации, анонсирования и хранения образовательных, научных, статистических и прочих данных.

Пентесты имитируют известные способы сетевых атак. Успешность теста на проникновения во многом зависит от полноты и качества составления профиля жертвы. Какими сервисами и программами пользуется жертва? На каких протоколах и портах у нее есть открытые подключения? С кем, как, и когда она общается? Почти все это можно получить из открытых источников. В статье мы рассмотрим популярные инструменты и техники пассивного сбора информации.
Определение почтовых адресов
Приступим к сбору информации. Начнем с самого простого, и что легче всего находится в сети. В качестве эксперимента я выбрал колледж в Канаде (al…..ge.com). Это наша учебная цель, о которой мы постараемся накопать как можно больше информации. По этическим соображениям часть адреса будет скрыта.
Чтобы заняться социальной инженерией, нам потребуется собрать базу почтовых адресов в домене жертвы. Заходим на сайт колледжа и переходим в раздел с контактами.
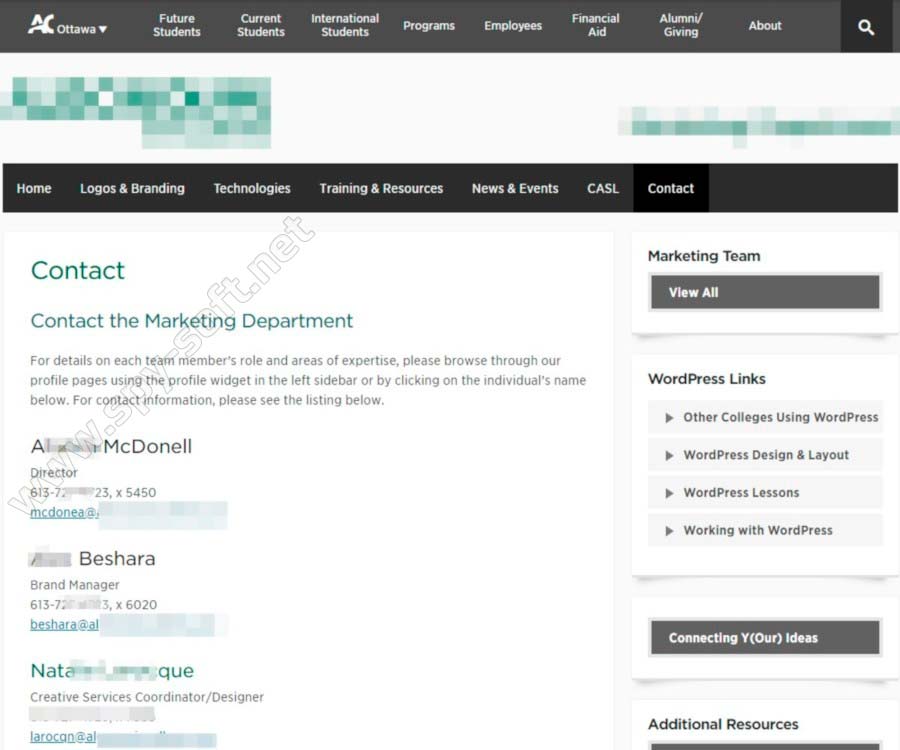 Раздел с контактами на сайте al..…ge.com
Раздел с контактами на сайте al..…ge.com
Там представлены одиннадцать адресов. Попробуем собрать больше. Хорошая новость в том, что нам не придется рыскать по сайтам в поисках одиночных адресов. Воспользуемся инструментом theHarvester. В Kali Linux эта программа уже установлена, так что просто запускаем ее следующей командой:
После нескольких минут утомительного ожидания получаем 125 адресов вместо 11 общедоступных. Хорошее начало, не правда ли?!
 Результат работы theHarvester
Результат работы theHarvester
Если у них доменная система, а почтовиком назначен сервер Exchange, то (как это обычно бывает) какой-нибудь из найденных почтовых ящиков наверняка будет доменной учетной записью.
Поиск по метаданным
На образовательных сайтах в открытом доступе лежит огромное количество документов. Их содержимое редко представляет интерес для пентестера, а вот метаданные — практически всегда. Из них можно узнать версии используемого ПО и подобрать эксплоиты, составить список потенциальных логинов, взяв их из графы «Автор», определиться с актуальными темами для фишинговой рассылки и так далее.
Поэтому мы соберем как можно больше метаданных. Для сбора метаданных мы воспользуемся утилитой FOCA — Fingerprinting Organizations with Collected Archives. Foca нам нужна только ради одной функции — сканирование определенного домена в поисках документов в популярных форматах с помощью трех поисковиков (Google, Bing и DuckDuckGo) и последующим извлечением метаданных. Утилита также умеет анализировать метаданные EXIF из графических файлов, но к сожалению в этих полях редко находится что-то интересное.
Запускаем FOCA, жмем на «Project» и создаем новый проект. В правом верхнем углу отмечаем все форматы и жмем на «Search All». Поиск занимает до 10 минут.
В итоге в главном окне FOCA мы видим огромное количество файлов, которые утилита нашла на сайте. В нашем случае большую часть составили документы PDF.
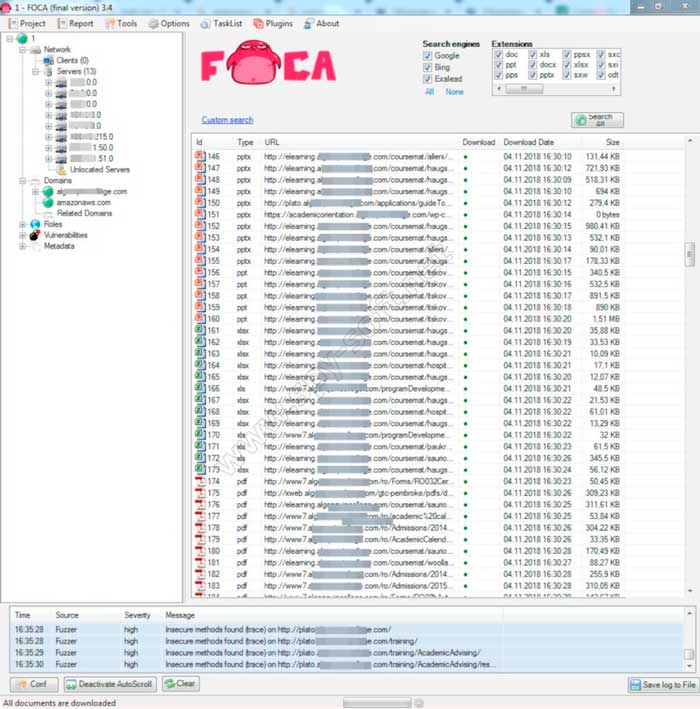 Результат поиска файлов с сайта программой FOCA
Результат поиска файлов с сайта программой FOCA
Следующий — это загрузка выбранных или всех файлы (контекстное меню → Download All) и после чего извлечение из них метаданных.
Давайте проанализируем, что нам удалось найти.
- Вкладка «Users» — 113 записей. В основном это имена пользователей, которые указываются при установке офисных пакетов. Они необходимы для последующей социальной инженерии и подбора пар логин-пароль к обнаруженным в домене сетевым сервисам.
- Вкладка «Folders» — 540 записей. Здесь есть каталоги, которые указывают на использование ОС Windows (что подтверждается в дальнейшем), и часто попадается строка вида N:…. Я думаю, что это сетевой диск, который как правило подключается скриптом при входе пользователя в систему.
- Вкладка «Printers» — 11 записей. Теперь мы знаем модели сетевых принтеров (они начинаются с \). Другие или локальные, или подключены через сервер печати.
- Вкладка «Software» — 91 запись. Здесь мы видим программное обеспечение, установленное на компьютерах. Самое интересное заключается в том, что указаны версии программ, из которых можно выбрать уязвимые и попробовать эксплуатировать их при атаке.
- Вкладка «Emails». Это мы и так имеем в достатке благодаря инструменту theHarvester.
- Вкладка «Operating Systems» — 5 записей. ОС, на которых создавались собранные нами файлы. Радует цифра 81 напротив Windows XP. Как правило, такие организации редко обновляют операционные системы. Есть большой шанс того, что старая версия Windows, для которой уже давно прекратили выпускать обновления безопасности, у них стоит по сей день.
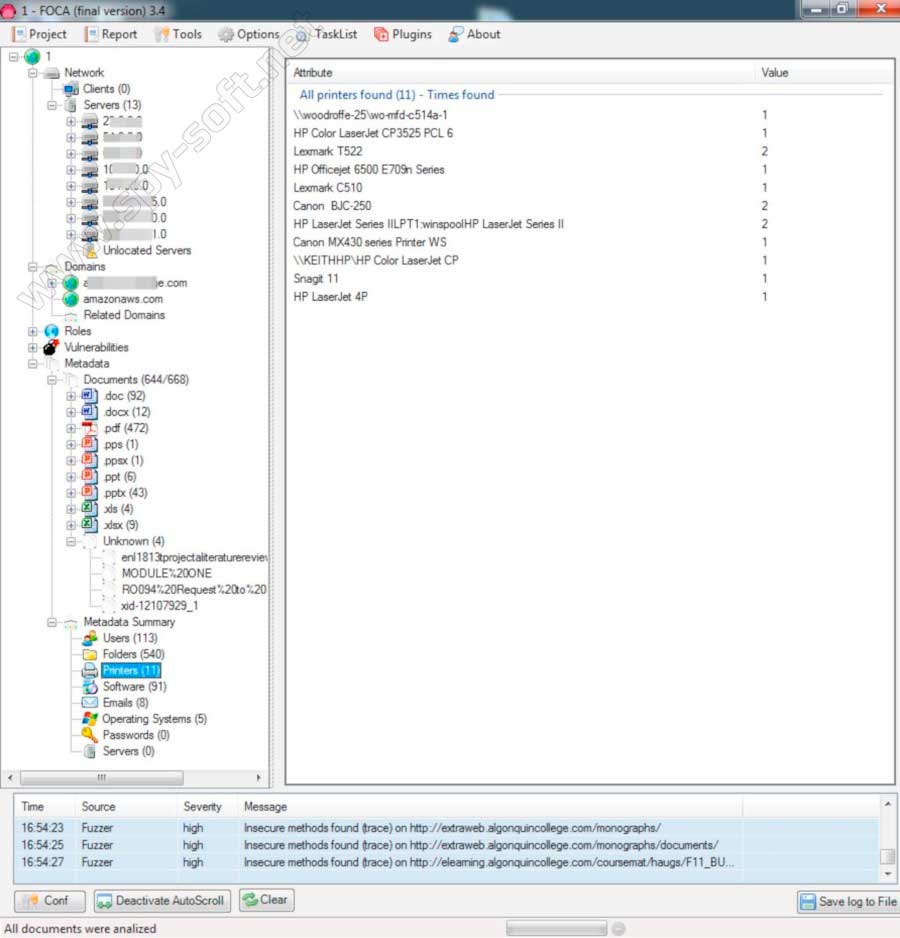 Метаданные, извлеченные FOCA
Метаданные, извлеченные FOCA
Получение данных о домене
Следующим этапом сбора информации — получение информацию о домене. Начнем с программы whois (подробнее о ней читайте в статье RFC 3912). Открываем терминал и вводим команду

