Допустим, нам нужно построить отчёт об ожидаемых оплатах от клиентов таким образом, чтобы эти оплаты были сгруппированы по месяцам. Заголовки колонок отчёта должны выглядеть так: "Июль 2017", "Август 2017", "Сентябрь 2017".
В качестве источника данных для отчёта мы используем запрос. Уже в запросе мы получаем данные, сгруппированные по месяцам, с помощью конструкции:
Весь запрос (в несколько сокращённом виде, для наглядности) выглядит так:
На вкладке "Наборы данных" настроим формат поля "ПериодПлатежа":
В колонке "Оформление" зададим формат даты таким образом: ДФ=’ММММ гггг’. Это даст нужное нам отображение месяца, вида "Июль 2017".
Поле "КОплате" мы делаем ресурсом в нашем отчёте, а настройки отчёта выполняем так:
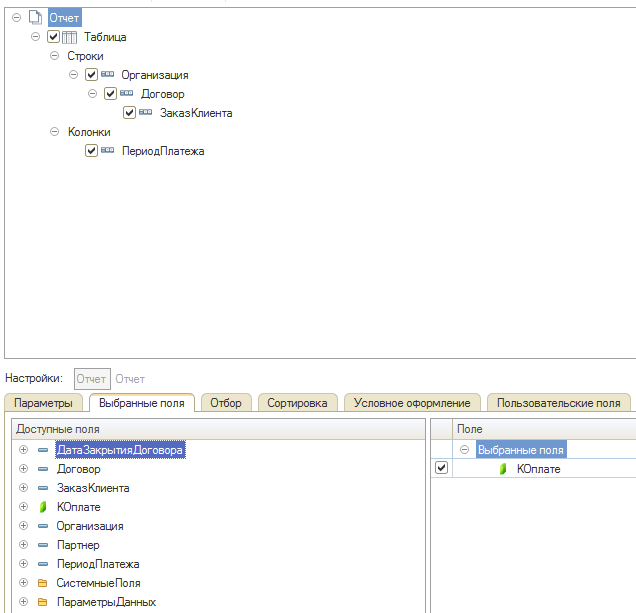
Всё бы хорошо, но при формировании отчёта наблюдаем такую вещь: если в каком-то месяце не ожидаются оплаты клиентов, то этот месяц не попадает в колонки отчёта. То есть, за колонкой "Август 2017" может идти колонка "Октябрь 2017". Чтобы в отчёт попал и "Сентябрь 2017", в котором не ожидается оплат, нужно настроить тип дополнения для группировки "ПериодПлатежа". Делается это в свойствах группировки. Тип дополнения выбираем "Месяц". После этого в отчёт попадут все месяцы по порядку.
Вопрос-ответ Отзывов (3) 
 В закладки
В закладки
Все дальнейшие примеры приведены для платформы 8.2.14.439 / Демонсрационная конфигурация УТ 11.0.4.5
Все сокращенные ссылки ведут в Google Docs (учетная запись не требуется)
Имеем самый простой запрос к виртуальной таблице “Остатков и Оборотов” регистра “ТоварыНаСкладах”.
Собственно схема компоновки: http://goo.gl/oIWhb
В схеме имеется поле – реквизит измерения “Склад”. Всем полям назначены корректные роли.
В настройках в группировках строк имеем группировку по номенклатуре
Добавляем вывод детальных записей (Поле Регистратор, Сортировка по регистратору).
В результате получаем корректные остатки по измерению номенклатуры, по детальным записям начальные и конечные
остатки, как и ожидалось “СКАЧУТ” – т.е. нарушается связь: начальный остаток записи равен конечному остатку предыдущей записи.
Исправляем предыдущую ситуацию – вместо детальных записей выводим группировку по регистратору.
Все отлично, т.е. так как и надо. Остатки по регистратору “не скачут”.
Добавляем группировку Колонок “Период месяц”. Так как с группировкой по регистратору вывести не получится, вместо группировки
по регистратору используем детальные записи с полем регистратор.
И возвращаемся к ситуации 1 
Хотелось бы обратить внимание как в данном случае выводятся остатки по регистратору – а именно в колонке периода месяц выводятся только
данные по регистраторам из ДАННОГО периода
Для того чтобы можно было сгруппировать по регистратору и по периоду, меняем в схеме компоновки у поля периода (в данном примере “ПериодМесяц”)
Настройку Роли, а именно снимаем флажок ДОПОЛНИТЕЛЬНОГО ПЕРИОДА
Теперь мы можем сгруппировать и по регистратору и по периоду. Выполняем. И опять облом
Теперь получается что по колонке периоду у всех регистраторов Начальный и Конечный Остатки одинаковы – соответственно Начальный и конечный остатки
по ТЕКУЩЕМУ периоду
(Результат конечно ожидаем, когда знаешь как СКД рассчитывает остатки – но сейчас не об этом)
Да и к тому же в колонке выводятся остатки и для регистраторов из других периодов (но с этим еще можно бороться)
Убил кучу времени чтобы реализовать и группировку строк по регистратору и группировку колонок по периоду так, чтобы остатки выводились корректно по регистраторам,
а именно – начальный остаток записи, равен конечному остатку предыдущей записи и т.д. – т.е. Примерно как при настройках в Ситуации 3, но чтобы остатки “не скакали”
Добиться желаемого результата (и оставить масштабируемость настроек и скорость работы отчета на приемлемом уровне) пока не удается
Если кто сталкивался с такой проблемой и знает решение или ссылки на информацию, которая поможет его найти – подскажите, пожалуйста.
На самом деле все мы помним замечательный Универсальный отчет, который легким движением руки позволял пользователю самому выбрать период развертки. В СКД пользователь тоже может это сделать сам, но для этого ему надо изменять вариант отчета, а, к сожалению, пользователи редко хотят и умеют это делать. Да и всё равно для этого необходимо создать список необходимых полей периодов.
Я же хочу показать, как это сделать для пользователя максимально наглядно и максимально очевидно для программиста.
Покажу 2 варианта, но существуют, конечно же, и другие. Можно, к примеру, в процедуре
Я хотел сделать всё исключительно в СКД, и такой способ тоже есть, более того, он, вероятно, даже проще. Я покажу два очень похожих варианта, смысл в двух — просто показать некоторые возможности СКД, которые кто-то, может быть, не знает.
Для начала создадим параметр, естественно, можно добавить или удалить какую-то свою периодичность.

Вариант 1.
Допустим, у нас в запросе фигурирует поле Дата, по нему мы и будем группировать. Прежде всего нужно привести дату к началу необходимого периода, я предпочитаю делать через выбор.
То есть мы получаем в одном поле любое нужное нам начало периода, но было бы неплохо выводить его не в виде даты, а удобно настроить формат. Для этого отредактируем Выражение представления, в настройках поля СКД.
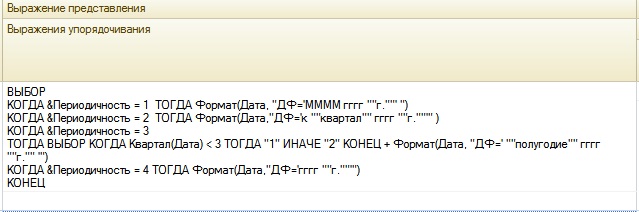
Естественно, можно настроить формат так, как хотите. Можно и не настраивать.
Осталось только добавить наше поле в структуру варианта и вынести параметр Периодичность в быстрые настройки, для удобства.

В общем-то, всё, почти динамическая группировка готова. Почему почти? Ну мы же должны заранее задать и описать необходимые периоды!
Вариант 2.
Этот вариант очень похож на первый, я тут просто покажу пару возможностей СКД. Тут мы, вместо одного поля Период, сделаем несколько полей. Месяц, Квартал, Полугодие, Год и т.д.
В запросе опишем эти поля вот таким образом
NULL обязателен, чтобы использовать одну из настроек СКД — "Игнорировать NULL". Если не хотите использовать NULL, то никто не мешает для каждой из 4 группировок создать свой собственный отбор на параметр Периодичность. Я это описывать не буду, думаю и так всё очевидно.

И создаем 4 группировки с этими полями.
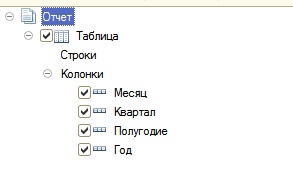
Мы так описали поля, что все, кроме одного периода, нужного нам, будут иметь значение NULL, и из-за настройки Игнорировать NULL они будут просто, внезапно, проигнорированы.

Так что в СКД избавляться от NULL нужно с умом 🙂 иногда оно бывает полезно.
На самом деле такой подход работает далеко не только для периода. Я подобным подходом пользуюсь в разных отчетах довольно часто
Специальные предложения














(1) Yashazz, можно и полями, собственно какая разница? 🙂
Я уже писал подобную статью, а почитав комментарии к ней, можно написать отличный отчет — http://infostart.ru/public/125216/
Самым правильным вариантом считаю составление текста запроса с учетом переданного параметра (задавать периодичность виртуальной таблицы) с последующей передачей внешнего набора данных (таблицы) в макет СКД.
Как-то так:
У меня только один вопрос. На каком основании Вы считаете, что этот метод "самый правильный"? Я вот так не считаю. К тому же далеко не всегда у нас виртуальная таблица оборотов используется в отчете.
(6) zqzq, да можно, но всё равно это не так удобно, однако как вариант почему нет. Я же написал — это один из вариантов. Мне удобнее делать так, кому-то удобнее иначе 🙂
зато есть необходимость менять текст запроса, создавать ТЗ, загружать его в СКД и прочее. А посчитать case для строчки дело не сложное, к тому же в моем примере идет сравнение чисел, что в общем-то вряд ли сильно затруднит обработку.
Но я так же могу поспорить и с фразой "правильный — значит быстродейственный." Мы пишем не на С++ и 1С сама по себе довольно медлительна и много где теряет производительность. Вообще код в 1С должен соблюдать баланс между скоростью работы и скоростью восприятия этого кода другим программистом. По моему сугубо личному мнению все эти обработки при компановке, передача ТЗ как внешний источник и прочие извращения это от криворукости, когда человек не может в СКД сделать нормальный запрос. И анализировать это разбирая процедуры, которые наваял автор бывает довольно проблемно. И если вы ради вычисления одного поля будете всё переносить в модуль, то. ну даже не знаю. Бывают ситуации, когда без этого не обойтись, но они бывают редко.
однако вариант с переносом расчета периода из запроса в вычисляемые поля он и правда с этой точки зрения лучше, тк всё воспринимается ещё легче.
Зачем? Это Вы должны обосновывать на каких таких основаниях вы считаете свой метод лучше и быстрее 🙂 я ничего не брался доказывать, просто рассказал более удобный способ.
Более того, я в начале сказал, что мы можем что-то сделать с СКД при компановке, но это совершенно не интересно.
Я только что специально протестировал этот механизм с использованием планировщика(только сам запрос), чтобы я ни делал выше 0% общая стоимость выполнения comptute scalar не превышала, там что-то в районе 0.000000014 общая стоимость. Поэтому истории про то, что тяжело рассчитать case для каждой строчки несколько надуманы.
Кстати что интересно в SQL запрос попадает не весь case а только верный вариант, не знаю с чем это связано пока.
А вам сказать, благодаря кому она такая медленная? или Сами догадаетесь? А тестировали вы на каких данных? Сколько строк в результирующем запросе? 10?
Программист пишет не так, чтобы это было легко сделать (очень близко к определению понятия "говнокод"), а так, чтобы это работа правильно и максимально быстро.
Да извольте анализировать процедуры, написанные автором. Все правильное реализуется непросто, а что реализуется просто — то поделка школьника. Возьмите к примеру запросы вычисления страховых взносов в ЗУПе — их тупо листать устанешь, не то что разбирать. А на первый взгляд, там сложного ничего нет — есть база и есть процент))
— в корне неправильный подход. Возвращаясь к вопросу о быстродействии 1с — чего вы хотели, если не используете возможности платформы (виртуальные таблицы в частности)?
А теперь по делу. Сделал регистр сведений, добавил туда пару полей и одно из полей Дата, добавил в него 510к строк. Судя по плану запроса вычисление периода тратит 1% от общего времени(ориентировочно)

Такие дела.
Да и, к слову, в 1С есть стандарты разработки, которые ставят качество восприятия кода на одну ступень с его быстродействием, за редчайшим исключением вроде процедур проведения, где каждая секунда важна.
И если по Вашему стоит из-за любого чиха обработку переносить в модуль, вместо СКД и считаете это правильным, то мне надо Вас огорчить. Сказать почему? Ну например СКД динамически формирует запрос и отборы в СКД автоматически переносятся в запрос тоже. Может случиться такая ситуация, что пользователю будет нужна одна строка, а вы создадите свою таблицу из миллиона записей в модуле и СКД всё равно отберет одну строку. поспорим о производительности? Или будете все допустимые отборы выносить на форму и обрабатывать в своем запросе? СКД автоматически работает с характеристиками. Но главная причина спора и производительность это тема тоже сложная. Я например абсолютно убежден, что сделать запрос на миллион строк и выгрузить его в ТЗ, а потом передать как внешний источник данных в СКД — нереально медленная операция, тут потери производительности на создание ТЗ просто громадны и они даже близко не сопоставимы с мизерными потерями на расчет периода в строке.
Да и просто анализировать единый запрос в СКД куда правильнее чем раскидывать код по модулям без причин.
Ваша статья несколько отличается от моей, спорить с этим бессмысленно. К тому же вы проповедуете несколько иные подходы. Вы предъявили мне претензии мол Ваш метод работает очевидно быстрее, но не приводите никаких доказательств и сравнений. Вместо этого пытаетесь оскорблять и придираться к несущественным аспектам, которые к статьей не имеют никакого отношения.
(10), я надеюсь на этом мы закончим нашу беседу, мне она не очень интересна, извините уж 🙂
Ну а зачем трюк с нуллом? Выбрал в запросе сразу поля, а скд откинет лишнее. Она даже соединения таблиц убирает, если поля не выбраны в настройках.
Прошу прощения, не так понял, вы не хотели заморачиваться с выбором вариантов.
(10) Lyns_owner, я тоже считаю, что ваш вариант с программным составлением явно не для СКД. Может вы вообще все за СКД сделаете и отдадите ей только те поля в запросе, которые в конкретном варианте настроек будут, да еще и отборы сразу наложите?
Хороший вопрос 🙂 нет тут дело немного в другом, в моем примере я именно "выбираю все поля", но те, где NULL, автоматически отсекаются. То есть если бы там не было NULL, они бы вывелись.
Вы же говорите про другое, то есть я гипотетически могу создать 4 поля(для 4-х периодов) и выводить только одно из них, а остальные сами отсекутся. Да, это так, но для этого надо вручную менять структуру отчета, чтобы включить только нужные поля. Я же хотел именно чтобы к структуре отчета пользователь даже не подходил. Но, справедливости ради, это и правда довольно нетипичный метод и в данном случае он излишне сложный 🙂 я его показал просто как пример работы с NULL.
Очень похожий способ используется в типовых конфигурациях, когда идет работа с таблицей ОстаткиИОбороты и надо вывести регистратор.

