Содержание
- 0.1 скомпилированный
- 0.2 Делаем Карту слов лучше вместе
- 0.3 Синонимы к слову «скомпилированный»
- 0.4 Предложения со словом «скомпилированный»
- 0.5 Понятия, связанные со словом «скомпилированный»
- 0.6 Отправить комментарий
- 0.7 Дополнительно
- 1 Цель данной статьи:
- 2 Этапы компиляции:
- 3 Заключение
- 4 Похожие публикации
- 5 Вакансии AdBlock похитил этот баннер, но баннеры не зубы — отрастут
- 6 Комментарии 27
СКОМПИЛИ’РОВАННЫЙ, ая, ое; -ван, а, о (книжн.). Прич. страд. прош. вр. от скомпилировать.
Источник: «Толковый словарь русского языка» под редакцией Д. Н. Ушакова (1935-1940); (электронная версия): Фундаментальная электронная библиотека
скомпилированный
1. страд. прич. прош. вр. от скомпилировать
Делаем Карту слов лучше вместе
 Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я обязательно научусь отличать широко распространённые слова от узкоспециальных.
Насколько понятно значение слова словенский (прилагательное):
Синонимы к слову «скомпилированный»
Предложения со словом «скомпилированный»
- Premiere лишь считывает из них информацию в проект, а затем (в соответствии с действиями пользователя по монтажу фильма) обрабатывает её с тем, чтобы представить скомпилированное изображение кадра фильма в окне Monitor (Монитор).
- В правой области окна Monitor (Монитор) по — прежнему демонстрируется скомпилированный кадр фильма, соответствующий программе окна Timeline (Монтаж).
- Приложение не будет скомпилировано.
- (все предложения)
Понятия, связанные со словом «скомпилированный»
Отправить комментарий
Дополнительно
Предложения со словом «скомпилированный»:
Premiere лишь считывает из них информацию в проект, а затем (в соответствии с действиями пользователя по монтажу фильма) обрабатывает её с тем, чтобы представить скомпилированное изображение кадра фильма в окне Monitor (Монитор).
В правой области окна Monitor (Монитор) по — прежнему демонстрируется скомпилированный кадр фильма, соответствующий программе окна Timeline (Монтаж).
Файл в формате CHM представляет собой скомпилированный HTML. В него могут входить HTML-страницы, рисунки, таблицы стилей, скрипты и другие файлы. Подробное описание состава CHM смотрите в материале Формат HTML Help. Результирующий файл в формате CHM не редактируется. Отредактировать можно только файлы, входящие в его состав. Извлечь файлы или декомпилировать CHM можно при помощи бесплатной программы HTML Help Workshop.
Чтобы декомпилировать выбранный для примера файл api.chm:
- На локальном диске, например на диске С, создайте папку для работы test и в ней подпапку decompiled.
- Скопируйте файл chm в папку test.
- Запустите HTML Help Workshop.
- Выберите File / Decompile.
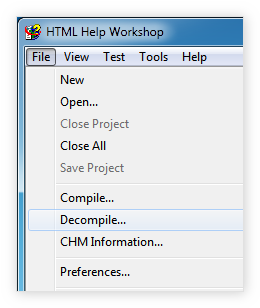
- В окне Decompile .CHM file: нажмите на кнопку Browse справа от поля Destination folder и выберите папку decompiled.
- В поле Compiled help file: аналогичным образом выберите файл chm.
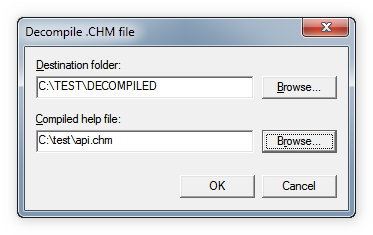
- Нажмите на кнопку ОК. На экран будет выведено сообщение о том, что 64 файла извлечено из файла chm.
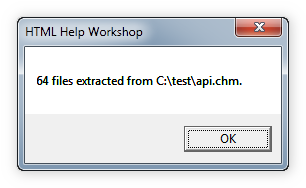
Это именно те файлы, которые мы будем редактировать. Рассмотрим их подробнее:
- CSS-файлы содержат таблицы стилей, определяющих внешний вид контента справки;
- Рисунки в формате GIF — это скриншоты и другие рисунки, использованные в CHM-файле;
- HTM-файлы соответствуют страницам разделов справки содержат текст, ссылки на рисунки, скрипты и т.д.
- файл api.hhc содержит оглавление справки;
- файл api.hhk содержит ключевые слова.
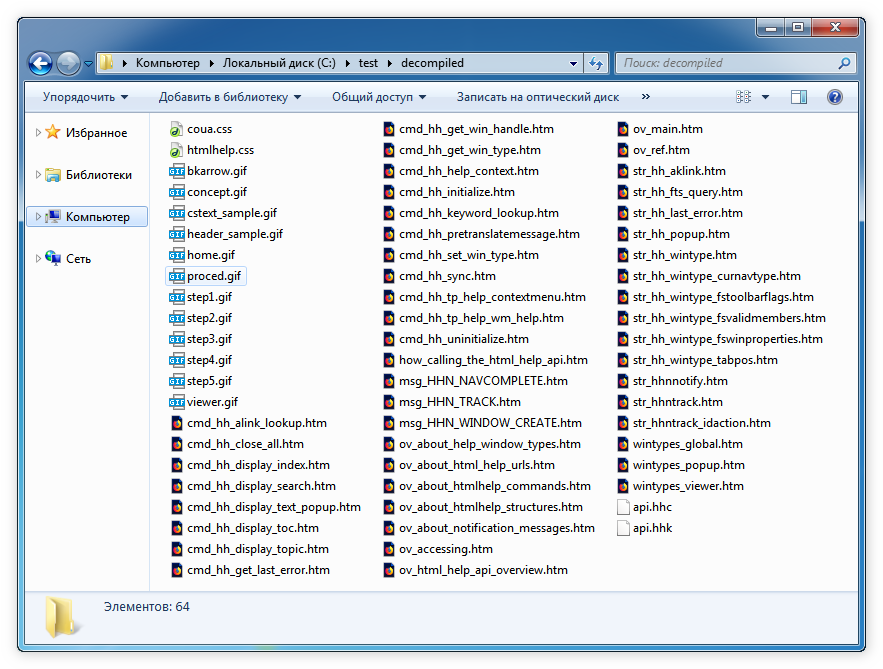
- Откройте в Проводнике папку C: estdecompiled и найдите в ней .htm-файл, который соответствует разделу справки, открываемому по умолчанию при запуске chm. Это файл ov_main.htm.
На этом декомпиляция CHM-файла завершена. Далее необходимо научиться собирать новый CHM-файл с функционалом, аналогичным оригиналу. Дело в том, что во время редактирования нужно будет периодически собирать CHM, чтобы в случае возникновения ошибок их было проще и быстрее найти. О том, как собрать новый CHM из полученных файлов, речь пойдет в следующем материале Создание и настройка проекта в HTML Help Workshop.
Цель данной статьи:
В данной статье я хочу рассказать о том, как происходит компиляция программ, написанных на языке C++, и описать каждый этап компиляции. Я не преследую цель рассказать обо всем подробно в деталях, а только дать общее видение. Также данная статья — это необходимое введение перед следующей статьей про статические и динамические библиотеки, так как процесс компиляции крайне важен для понимания перед дальнейшим повествованием о библиотеках.
Все действия будут производиться на Ubuntu версии 16.04.
Используя компилятор g++ версии:
Состав компилятора g++
Мы не будем вызывать данные компоненты напрямую, так как для того, чтобы работать с C++ кодом, требуются дополнительные библиотеки, позволив все необходимые подгрузки делать основному компоненту компилятора — g++.
Зачем нужно компилировать исходные файлы?
Исходный C++ файл — это всего лишь код, но его невозможно запустить как программу или использовать как библиотеку. Поэтому каждый исходный файл требуется скомпилировать в исполняемый файл, динамическую или статическую библиотеки (данные библиотеки будут рассмотрены в следующей статье).
Этапы компиляции:
Перед тем, как приступать, давайте создадим исходный .cpp файл, с которым и будем работать в дальнейшем.
driver.cpp:
1) Препроцессинг
Самая первая стадия компиляции программы.
Препроцессор — это макро процессор, который преобразовывает вашу программу для дальнейшего компилирования. На данной стадии происходит происходит работа с препроцессорными директивами. Например, препроцессор добавляет хэдеры в код (#include), убирает комментирования, заменяет макросы (#define) их значениями, выбирает нужные куски кода в соответствии с условиями #if, #ifdef и #ifndef.
Хэдеры, включенные в программу с помощью директивы #include, рекурсивно проходят стадию препроцессинга и включаются в выпускаемый файл. Однако, каждый хэдер может быть открыт во время препроцессинга несколько раз, поэтому, обычно, используются специальные препроцессорные директивы, предохраняющие от циклической зависимости.
Получим препроцессированный код в выходной файл driver.ii (прошедшие через стадию препроцессинга C++ файлы имеют расширение .ii), используя флаг -E, который сообщает компилятору, что компилировать (об этом далее) файл не нужно, а только провести его препроцессинг:
Взглянув на тело функции main в новом сгенерированном файле, можно заметить, что макрос RETURN был заменен:
В новом сгенерированном файле также можно увидеть огромное количество новых строк, это различные библиотеки и хэдер iostream.
2) Компиляция
На данном шаге g++ выполняет свою главную задачу — компилирует, то есть преобразует полученный на прошлом шаге код без директив в ассемблерный код. Это промежуточный шаг между высокоуровневым языком и машинным (бинарным) кодом.
Ассемблерный код — это доступное для понимания человеком представление машинного кода.
Используя флаг -S, который сообщает компилятору остановиться после стадии компиляции, получим ассемблерный код в выходном файле driver.s:
Мы можем все также посмотреть и прочесть полученный результат. Но для того, чтобы машина поняла наш код, требуется преобразовать его в машинный код, который мы и получим на следующем шаге.
3) Ассемблирование
Так как x86 процессоры исполняют команды на бинарном коде, необходимо перевести ассемблерный код в машинный с помощью ассемблера.
Ассемблер преобразовывает ассемблерный код в машинный код, сохраняя его в объектном файле.
Объектный файл — это созданный ассемблером промежуточный файл, хранящий кусок машинного кода. Этот кусок машинного кода, который еще не был связан вместе с другими кусками машинного кода в конечную выполняемую программу, называется объектным кодом.
Далее возможно сохранение данного объектного кода в статические библиотеки для того, чтобы не компилировать данный код снова.
Получим машинный код с помощью ассемблера (as) в выходной объектный файл driver.o:
Но на данном шаге еще ничего не закончено, ведь объектных файлов может быть много и нужно их всех соединить в единый исполняемый файл с помощью компоновщика (линкера). Поэтому мы переходим к следующей стадии.
4) Компоновка
Компоновщик (линкер) связывает все объектные файлы и статические библиотеки в единый исполняемый файл, который мы и сможем запустить в дальнейшем. Для того, чтобы понять как происходит связка, следует рассказать о таблице символов.
Таблица символов — это структура данных, создаваемая самим компилятором и хранящаяся в самих объектных файлах. Таблица символов хранит имена переменных, функций, классов, объектов и т.д., где каждому идентификатору (символу) соотносится его тип, область видимости. Также таблица символов хранит адреса ссылок на данные и процедуры в других объектных файлах.
Именно с помощью таблицы символов и хранящихся в них ссылок линкер будет способен в дальнейшем построить связи между данными среди множества других объектных файлов и создать единый исполняемый файл из них.
Получим исполняемый файл driver:
5) Загрузка
Последний этап, который предстоит пройти нашей программе — вызвать загрузчик для загрузки нашей программы в память. На данной стадии также возможна подгрузка динамических библиотек.
Запустим нашу программу:
Заключение
В данной статье были рассмотрены основы процесса компиляции, понимание которых будет довольно полезно каждому начинающему программисту. В скором времени будет опубликована вторая статья про статические и динамические библиотеки.
Читают сейчас
Похожие публикации
- 4 июля 2012 в 13:15
Подсчет ссылок атомарными переменными в C/C++ и GCC
Qt/Objective-C++11 или сборка Qt-проекта с помощью GCC-4.7 и Clang
Gcc vs Intel C++ Compiler: собираем FineReader Engine for Linux
Вакансии
AdBlock похитил этот баннер, но баннеры не зубы — отрастут
Комментарии 27
Возможно статья не станет откровением для тех, кто хорошо знаком с языком, но мне было интересно почитать.
Статье не хватает больше подробностей про каждый этап, имхо.
Интерпретаторы С и С++ тоже существуют, например cling, однако носят скорее теоретическую ценность.
носят скорее теоретическую ценность.
PicoC вполне удавалось юзать IRL 🙂
дополнение — ассемблер обычно вручную вызывать не надо
Сразу получаем объектник, а потом линкуем их в правльном порядке, с правильными библиотеками
Нужно заметить, что линковка в нужном порядке — особенность не всех линкеров.
Помнится, линкер студии справлялся с библиотеками без правильного порядка.
Но это мелочи.
Флажки —start-group/—end-group у ld(1) позволяют не думать о зависимостях между объектными файлами.
Ух ты, я был уверен, что компиляция с промежуточным компилированием в ассемблер осталась далеко в прошлом.
А что мешает компилировать сразу в исполняемый код? И, как я понимаю, другие языки такой подход не используют, или я не прав?
Компиляция с явной генерацией полноценного файла для ассемблера — это подход в первую очередь GCC. Даже во многом близкий к нему Clang не делает это основным методом — он вместо этого строит представление на LLVM IR в памяти и, если не сказано иное флагами, уже из него генерирует объектный файл без ассемблера. (Но его можно попросить выдать как IR в текстовом виде, так и код для ассемблера).
Компиляторы, созданные в других традициях — например, MSVC — такого не делают; их можно попросить сделать листинг в ассемблере, но этот листинг нельзя потом скормить ассемблеру, чтобы получить объектный файл.
Причины такой двухстадийности gcc, по-моему, в его истории: у Столлмана получилось нормально сделать и лицензионно, и по сути результата — конверсию в задокументированный ассемблер на целевых платформах первого поколения (таких, как SunOS, HP-UX, AIX), но уже объектный формат имел сложновыясняемые и/или лицензионно недоступные особенности. Сейчас не нагуглилось, так что это обоснование только по воспоминаниям о прочитанном и услышанном около 20 лет назад. Потом же решили не менять этот подход, потому что он оказался вполне недорогим (по сравнению как с парсингом C++, так и с ценой преобразований программы в процессе компиляции), даже с промежуточным файлом.
И ещё вкусность — наличие полноценного ассемблерного исходника, который можно посмотреть и, если нужно, подправить под себя, очень помогло в росте белой хакерской культуры. Помню это по себе — если что не понимаешь, смотришь ассемблер и экспериментируешь и в нём тоже 🙂
С другими языками — опять же, кто компилирует:) Все языки из комплекта GCC (C, C++, Fortran, Ada. ) или LLVM-based проходят такую фазу, обязательно или опционально. Аналогично, например, Go, но у него существенно свой ассемблер (причём на всех платформах; это мини-кошмар для системщика на x86 — кроме AT&T и Intel syntax, есть ещё Go syntax). В Unix мире много компиляторов переводят код своего языка на C, и уже этот результат компилируют, чтобы не заморачиваться после этого проблемами оптимизации; тогда тоже есть ещё фаза ассемблера.
Компилирование в ассемблер вместо объектного кода — традиционная манера 60-х годов, призванная упростить и уменьшить компилятор за счет времени компиляции.
Компилятор С исходно был сделан точно так же.
Без знания ассемблера бесполезно читать подобные статьи.
Пока не знаешь, как процессор работает с памятью, как вызываются процедуры… все рассуждения так и останутся пассами рук, магией.
Для тех, кто хочет реально разобраться, лучший способ что-то понять — сгенерировать компилятором ассемблерный листинг и изучить его, для начала лучше с отключенными оптимизациями. Будет повод узнать про ассемблер, что и как. Потом разберётесь, как устроена реализация объектов ООП и пр. Это действительно красиво.
Потом станет понятнее, зачем нужны obj-файлы и связывание, а уж как работает загрузка исполняемых файлов…
… После этого вы станете презирать интерпретаторы ))
Ну, как бы, интерпретация и компиляция — разные вещи со своими плюсами и минусами.
И просто презирать интерпретаторы(кстати, какие именно) попахивает максимализмом юношеским.

