Содержание
который поможет получить напечатанный текст из PDF документов и фотографий
Принцип работы ресурса
Отсканируйте или сфотографируйте текст для распознавания

Загрузите файл
Выберите язык содержимого текста в файле

После обработки файла, получите результат * длительность обработки файла может составлять до 60 секунд
- Форматы файлов
- Изображения: jpg, jpeg, png
- Мульти-страничные документы: pdf
- Сохранение результатов
- Чистый текст (txt)
- Adobe Acrobat (pdf)
- Microsoft Word (docx)
- OpenOffice (odf)
Наши преимущества
- Легкий и удобный интерфейс
- Мультиязычность
Сайт переведен на 9 языков - Быстрое распознавание текста
- Неограниченное количество запросов
- Отсутствие регистрации
- Защита данных. Данные между серверами передаются по SSL + автоматически будут удалены
- Поддержка 35+ языков распознавания текста
- Использование движка Tesseract OCR
- Распознавание области изображения (в разработке)
- Обработано более чем 5.8M+ запросов
Основные возможности

Распознавание отсканированных файлов и фотографий, которые содержат текст
Форматирование бумажных и PDF-документов в редактируемые форматы
Приветствуем студентов, офисных работников или большой библиотеки!
У Вас есть учебник или любой журнал, текст из которого необходимо получить, но нет времени чтобы напечатать текст?
Наш сервис поможет сделать перевод текста с фото. После получения результата, Вы сможете загрузить текст для перевода в Google Translate, конвертировать в PDF-файл или сохранить его в Word формате.
OCR или Оптическое Распознавание Текста никогда еще не было таким простым. Все, что Вам необходимо, это отсканировать или сфотографировать текст, далее выбрать файл и загрузить его на наш сервис по распознаванию текста. Если изображение с текстом было достаточно точным, то Вы получите распознанный и читабельный текст.
Сервис не поддерживает тексты написаны от руки.
Поддерживаемые языки:
Русский, Українська, English, Arabic, Azerbaijani, Azerbaijani — Cyrillic, Belarusian, Bengali, Tibetan, Bosnian, Bulgarian, Catalan; Valencian, Cebuano, Czech, Chinese — Simplified, Chinese — Traditional, Cherokee, Welsh, Danish, Deutsch, Greek, Esperanto, Estonian, Basque, Persian, Finnish, French, German Fraktur, Irish, Gujarati, Haitian; Haitian Creole, Hebrew, Croatian, Hungarian, Indonesian, Icelandic, Italiano, Javanese, Japanese, Georgian, Georgian — Old, Kazakh, Kirghiz; Kyrgyz, Korean, Latin, Latvian, Lithuanian, Dutch; Flemish, Norwegian, Polish Język polski, Portuguese, Romanian; Moldavian, Slovakian, Slovenian, Spanish; Castilian, Spanish; Castilian — Old, Serbian, Swedish, Syriac, Tajik, Thai, Turkish, Uzbek, Uzbek — Cyrillic, Vietnamese
© 2014-2019 img2txt Сервис распознавания изображений / v.0.6.5.0
Очень часто возникает необходимость распознать отсканированный текстовый документ, внести в него изменения или скопировать текс в другой файл. С этой задачей хорошо справляется специальная программа Microsoft Document Imaging. Мы расскажем, как с ее помощью скопировать текст со сканированного текстового документа.
Копируем сканированный текст
- Запускаем программу Document Imaging. Для этого заходим в меню «Пуск», выбираем раздел «Все программы» (в старых версиях операционной системы раздел называется просто «Программы»).
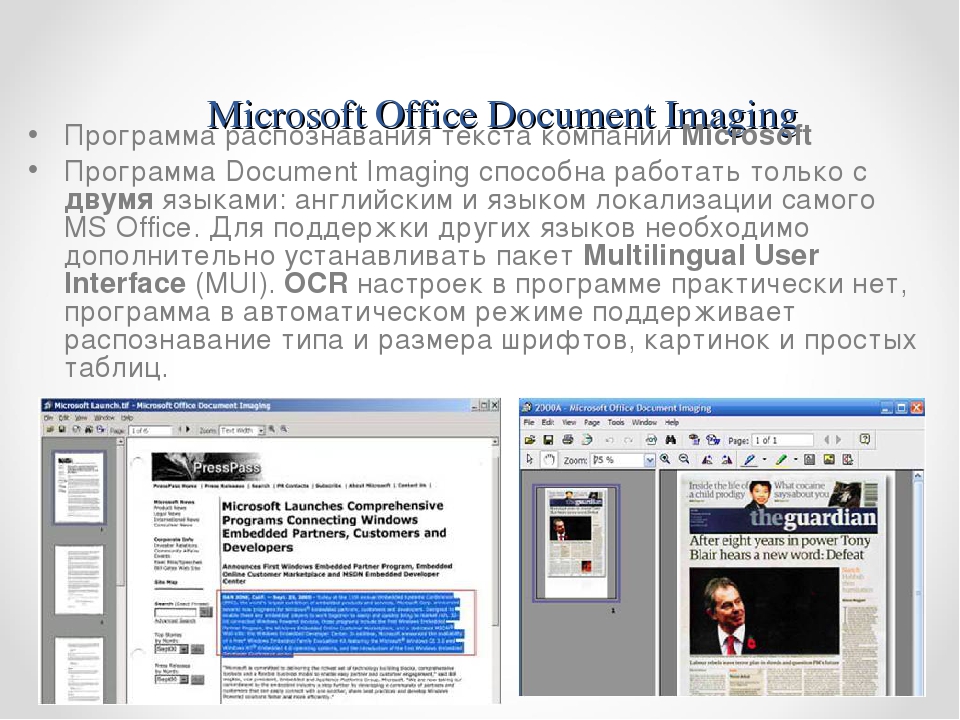
- В главном окошке программы в закладке «Файл» нужно выбрать опцию «Открыть». Здесь указываем месторасположение отсканированного файла и нажимаем «Ок».
- Теперь необходимо задать команду «Распознать» в опции «Сервис». В зависимости от ПО эта команда может располагаться в закладке «Файл».
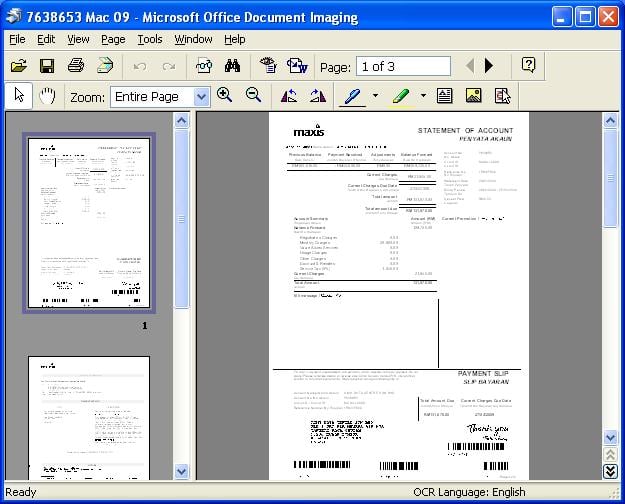
- После распознавания текстовый документ можно копировать и вставлять в любой другой файл. При копировании стоит помнить, что выделять необходимо все слово целиком, то есть доводить нужно до последней литеры.
- Текст выделяется рамочным способом. Необходимо перейти в меню «Вид» и выбрать «Выделить». После выделения фрагмента текста, необходимо нажать на опцию «Правка» и задать команду «Копировать».
- Теперь переходим в другой текстовый документ, выбираем опять меню «Правка» и команду «Вставить». Или же можно воспользоваться контекстным меню документа.
Как распознать текстовый документ для копирования?
Для этого необходимо запустить специальную программу, лучше всего FineReader.
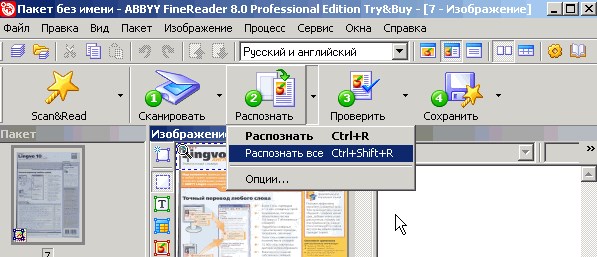
Перейдите в опцию «Распознать» — «Открыть изображение». Выберите нужный файл. На экране появятся изображения скан-копий. Справа будет результат распознавания.
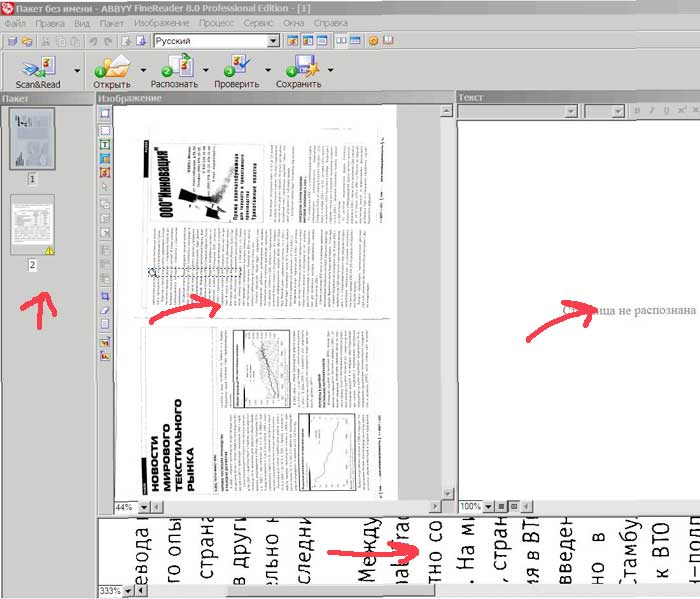
Для удобства можно развернуть скан-копию (если она альбомной ориентации), для этого стоит воспользоваться соответствующими кнопками. Затем указать программе, какую часть необходимо распознать и какой формат данных получится на выходе – табличка, картинка, текст. Каждый фрагмент документа будет выделен своим цветом: текст – зеленым, картинки, диаграммы, фото – красным, таблицы – синим.

После этого страницы нужно выделить с помощью сочетания клавиш Ctrl+A и нажать на опцию «Распознать». Сохраняем полученный документ Word нажатием кнопки «Сохранить» в верхнем меню. Теперь из текстового документа можно копировать любые фрагменты текста, таблицы, изображения.
Главное нужно указать изображение с текстом на вашем компьютере или телефоне, обязательно выбрать основной язык текста и нажать кнопку OK внизу страницы. Остальные настройки уже выставлены по умолчанию.
Пример сфотографированного текста из книги и скриншот распознанного текста на этой фотографии: 

В зависимости от размера исходного изображения и количества текста обработка может продлиться около 1 минуты.
Для достижения лучшего результата распознания текста желательно обратить внимание на подсказки возле настроек. Перед обработкой изображение нужно повернуть на нормальный угол, чтобы текст шёл в правильном направлении и небыл перевёрнут вверх ногами, а также желательно обрезать лишние однотонные края без текста, если они есть.
Обе OCR-программы для распознования текста отличаются друг от друга и могут давать разные результаты, что позволяет выбрать наиболее приемлемый вариант из двух.
Исходное изображение никак не изменяется, вам будет предоставлен распознанный текст в обычном текстовом документе в формате .txt с кодировкой utf-8 и после обработки его можно будет открыть прямо в окне браузера или же после скачивания – в любом текстовом редакторе.

