Содержание
Иногда нужно делать парсинг тяжёлых csv документов. Можно попытаться выполнить подобную задачу средствами PHP. Но как поведёт себя скрипт, если csv — файл весит 100 Мб. Скрипт не отработает. Произойдёт ошибка. Возможно не хватит оперативной памяти сервера. В этом случае есть выход: нужно разделить один большой csv файл на несколько маленьких. Таким образом вы снизите нагрузку на сервер.
Предлагаю вам своё решение. Посмотрите на файл для парсинга. Я не стал делать его большим, но вы должны понимать, что размер файла может быть достаточно большим. Вся сложность в том, что нужно скопировать названия столбцов и несколько раз вставлять в маленькие файлы. Как только большой файл будет поделён на части, то необходимо вставить названия столбцов в самое начало маленьких файлов. Содержимое большого файла должно быть поделено на равные части и записано в маленькие файлы. В этом заключается вся трудность. Если в csv файле нет первой строки с названиями столбцов, то это не правильный по составу файл.
Теперь рассмотрим сам скрипт sh для разделения csv файла на куски. Перед тем как запустить скрипт создайте папку parts для записи небольших файлов. Логика работы скрипта:
- Копирую файл file1.txt. Получается новый файл file2.txt без первой строки. На первой строке у нас были названия столбцов.
- Очищаю папку parts от старых файлов
- Из оригинального файла file1.txt беру названия столбцов и записываю в переменную header
- Разбиваю данные из файл file2.txt на маленькие файлы.
- Вывожу данные на экран для понимания работы скрипта
- При помощи цикла for добавляю в каждый файл названия столбцов
- При помощи цикла for меняю названия файлам file1.txt
Обратите внимание на переменную num_rows_new. Документ будет разбит по количеству строк согласно переменной num_rows_new. В итоге у вас будут масса файлов с одинаковым количеством строк, но последний файл будет отличаться от всех остальных. В нём будет наименьшее количество строк по остаточному принципу: 3 + 3 + 3 + 3 + 1 = 13. В последнем документе будет всего 2 строки. Одна с названиями столбцов, другая с данными. Вы можете не переименовывать файлы. В этом случае получится масса файлов с непонятными названиями: xaa, xab. Я советую вам переименовывать файлы. Так порядка больше. В итоге у вас получится несколько файлов. Я выводу содержимое всех файлов без разрывов.
Я для примера использовал файл с 13 строками (данные). Вы можете сделать большой файл на несколько мегабайт и разделить его на несколько скриптов.
and some other stuff
Из прошлой статьи про чтение огромадного CSV в C# вытекло целое приложение, предназначенное для распиливания такого файла на более мелкие части, чтобы с ними можно было работать.
В общем, я написал приложение, которое разделяет исходный невероятных размеров (несколько гигабайт, скажем) CSV файл на множество более мелких, чтобы с ними можно было работать хоть в Блокноте. Если помните, проблема с CSV в несколько гигабайт заключается в том, что для его чтения потребуется также несколько гигабайт оперативной памяти, что пока ещё является некоторой роскошью.
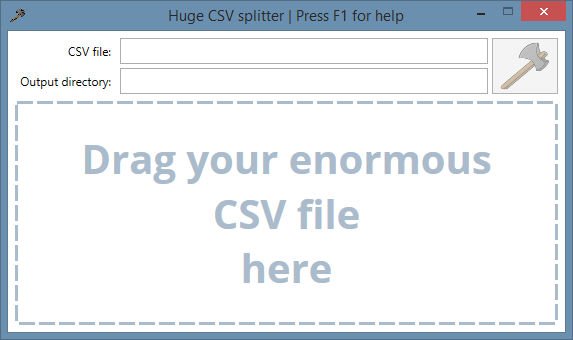
- Перетащить исходный CSV файл в область, обозначенную пунктирной линией (либо два раза кликнуть в первое поле ввода и выбрать файл, либо вставить туда путь до файла);
- Задать путь, куда будут складываться новые отрезанные CSV файлики (также два раза ткнув во второе поле ввода, либо вставив туда путь). Если поле оставить пустым, то файлы будут складываться в каталог с исходным;
- Нажать на кнопку с топором.
По нажатию на F1 появляется окно справки.
Приложение тестировалось в Windows 8.1 , но должно работать в любой, главное чтобы был установлен .NET Framework 4.5.1 .
В .config файле есть некоторые настройки.
linesPerFile
Через сколько строк разрезать. Например, если задать 1000 , то исходный файл будет читаться в буфер до 1000 строки, после чего буфер скинется в новый файл, и с 1001 строки будет заполняться по новой. И так до конца исходного файла.
Если строки достаточно короткие, то можно ставить значение побольше, от 500000 , скажем. Если довольно большие — лучше не ставить больше 100000 .
addHeader
Если поставить True , то в каждый новый файл первой строкой будет писаться первая строка исходного файла. Такое может понадобиться, если исходный файл содержит “шапку”. По умолчанию выставлено именно True .
Для запуска нужна только папка binRelease , остальное можете удалить. Из самой папки нужны только эти файлы:
- hugeCSVsplitter.exe
- hugeCSVsplitter.exe.config
- Ookii.Dialogs.Wpf.dll
Можете оставлять замечания/предложения на этой странице либо тут в каментах.
В общем есть огромный файл CSV размером 1,5Гб.
Который мне нужно распарьсить и написать для нее миграцию.
Я как обычно написал простой скрипт по обработке файла, но к сожаления шелл все время вешается.. = (
Суть вопроса, можно ли файл, как нибудь разбить, на отдельные CSV файлы? Примерно по 100МБ?
При этом нужно учитывать конец строки CSV?

